

Planning tasks and motions for robotic manipulators like arms and hands is one of the areas in which members of Rice University’s Kavraki Lab excel. The lab is widely recognized for its contributions to the field and its pioneering methods, so it is ironic that failure is the theme of a recent paper presented by Rice CS doctoral student Tianyang Pan and postdoc Rahul Shome at the International Conference on Robotics and Automation (ICRA).
“If we have a perfect model of the real-world environment in which our robot engages, the plans we compute can be executed with zero failures,” said Pan. “However, since the real world will always include exceptions—from unmodeled physics and system errors to malfunctioning grippers and distractions like a cluttered environment—when we execute valid plans in the real world, the robot can still experience failure. Can that failure be utilized as a teaching moment? Our goal with this paper was to combine traditional planning with reasoning about real-world failures to improve robot performance.
Pan and Shome’s research builds on the traditional method—also known as task and motion planning (TAMP)—that is an algorithmic way to let robots make decisions based on a given model of the world. The Kavraki Lab has been incorporating algorithm-based methods to solve robotic planning problems for over 20 years.
In their paper, Shome and Pan enhance traditional task and motion planning with the ability to reason over real execution failures, where a robot has to find a total set of tasks or motions that achieve the overall goal it was given.
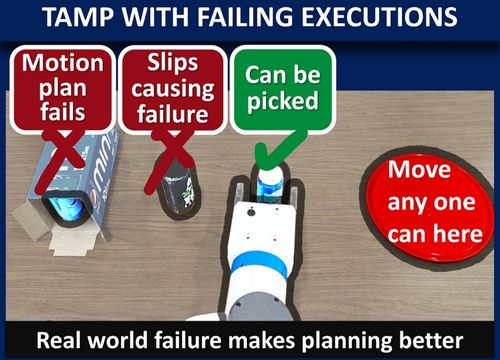 Shome referenced a scenario where you might ask the robot, “Can you make me a cup of coffee?”
Shome referenced a scenario where you might ask the robot, “Can you make me a cup of coffee?”
He said, “The robot in the lab might know what a coffee mug looks like and the sequence of steps to take the mug to the coffee machine and make coffee. When the robot ships from the lab to your home, it might come across your lucky mug that has a broken handle. The robot could fail to pick up that mug because it has not previously encountered a broken handle.
“Humans adapt quickly to the unexpected; our robot will have to similarly adapt, overcome the immediate problem, complete the task by choosing a different mug from the cupboard, and continue improving the way it solves problems - not just for the next one thing it needs to do—but for the next set of actions it will require to make coffee in your home every day. This is where planning with failures in mind really shines.”
Pan agreed. “The contribution of our paper becomes significant where there are multiple ways to finish a task. If there is only one way—one action that can finish a task—the only thing we or the robot can do is keep retrying that action, even when it is not working.
“Let’s think about robotic manipulation from the perspective of a small child who wants a drink. She is faced with a table of bottles. Some may be too heavy. She might try once or twice but quickly determines that bottle or task is just too hard. Some of the bottles may be slippery, with a probability of failure due to dropping one. Humans can quickly distinguish among the different bottles or different actions and find the one that is most likely to fulfill the goal—in her case, satisfying her thirst with a drink.
“We as humans don’t need to collect a lot of data by trying to grasp each bottle hundreds of times before we choose the more robust actions. As the authors illustrate in their short video "Failure is an option: Task and Motion Planning with Failing Executions,” their work is actually consistent with that human reasoning philosophy. That is the main contrast of our work to traditional deep learning-based methods, which are very data-hungry.”
Shome acknowledged the gap between training a robot in a controlled environment like a lab and then sending it out to work in the real world where it needs reasoning skills.
“It is not feasible to send a robot into a real-world environment without minimal knowledge about how to interact with the world. But if the robot knows enough about the problem when it reaches the real-world environment, it can use algorithmic rules to begin attempting the task, then deliberate over sequences of interactions - including its failures - to continue solving and improving its solutions,” said Shome.
“It is also important to note that our advances in TAMP are coupled with the advancements of the engineers who are building the robots. Robots—in my opinion—are just tools. We as researchers keep trying to make these tools work better and become more powerful. With more power comes more opportunities, not to just show off our research or make cool videos, but to push the boundaries of the usefulness of robots in society and to positively impact communities.”
Pan is similarly motivated by the potential applications of his research. He believes robots will be crucial in the future because of their capacity to enhance human life experiences, from health to work assistance.
He said, “We’ve already seen some cases where robots were able to help people all around the world during the pandemic. In other scenarios, we urgently need fully autonomous robots. For example, it would be great to deploy robots in dangerous rescue environments like fires or earthquakes, or exploring other planets.
“Robotics is truly an interdisciplinary field. We need mechanical and electrical engineers to design and build the robots, and computer scientists to help train the robots to think and plan for complex tasks. Our TAMP research is important to me personally because for robots to change the world, they will have to interact with the world, and planning enables that interaction.”
In her collaboration with Pan and Shome, Lydia Kavraki demonstrated the kind of leadership and partnership that both researchers said they have come to treasure. Kavraki, who wears many hats—Noah Harding Professor of Computer Science, professor of Bioengineering, professor of Electrical and Computer Engineering, professor of Mechanical Engineering, and Director of Rice’s Ken Kennedy Institute—also treasures the time she gets to spend in research with her team members.
She said, “Learning from failures in robot motion planning is an open field and the research of Tianyang and Rahul lays the foundations for making robots deployable in real scenarios. I was amazed at their inventiveness and persistence in getting this paper done and I was impressed by the real-robot demonstrations of their work.”
Tianyang Pan is a Computer Science Ph.D. candidate, advised by Lydia Kavraki. He matriculated at Rice University in 2019, after completing his M.S. in Electrical and Computer Engineering from the University of Michigan, Ann Arbor.
Rahul Shome is completing a postdoctoral appointment as a Rice Academy fellow at the Kavraki Lab before moving to Canberra, Australia where he will continue his research and teaching as a tenure-track faculty at the Australian National University.
Andrew Wells, who contributed to the initial stages of this work, is now a Tesla Autopilot senior software engineer. He completed his Ph.D. in Computer Science as a member of the Kavraki Group in 2021.