

With a glance, the human eye transfers image data to the brain for rapid identification and analysis. A similar model for computer systems was recently improved by Rice University computer scientists Vicente Ordóñez and Ziyan Yang, adding depth and detail to these analyses.
“When we look at an image for a specific object, we don't pay the same attention to all regions equally. Vision-and-language models perform a similar prioritization; we try to take advantage of this property to improve a model’s ability to attend to the right parts of the image. Anyone with a web browser or mobile phone can test our interactive model by uploading a photo and entering a key search term or phrase,” said Ordóñez, an associate professor of computer science at Rice and director of the Vision, Language, and Learning (vislang) Lab.
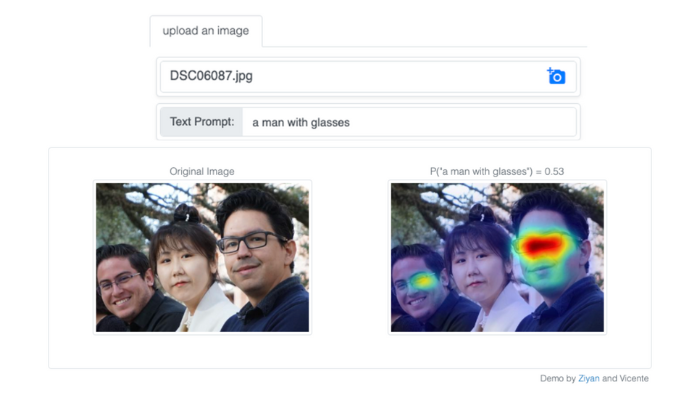
The interactive demo is driven by an improved model for localizing arbitrary objects and phrases in images, work that Yang will be presenting with their proposed Attention Mask Consistence (AMC) objective at the 2023 Conference for Computer Vision and Pattern Recognition (CVPR).
She said, “Our current work involves visual grounding, a typical vision language task that trains the model to understand signals from both images and text. Using this blended input, the model can localize the objects mentioned in the text on the image to form an appropriate and complete understanding of the whole. Thus, when the model is given text about the image — including nouns such as ‘an apple on a table’ — it should respond by localizing those objects in the image.”
Visual grounding has previously been accomplished through object detectors which focus attention on items inside a bounding box. To create the object detector training data, professional annotators draw a bounding box around each object that is important, then use text to describe the contents within the box.
“This type of annotation is expensive and not perfect,” said Yang. “It is difficult for a person to annotate everything in an image, some datasets might have many oranges and apples annotated with boxes but not grapes or peaches.
"By combining these limited annotated datasets with larger datasets of images with text, we are able to teach models how to recognize and localize a wider set of objects. We also wondered if we could get rid of the need to train object detectors and instead tune a model directly with bounding box annotations, gaining the benefits of bounding box focus and the ability of vision-language models to work with an arbitrarily large vocabulary of objects.”
The team realized that vision-and-language models are already capable of providing basic visual explanations through heat maps obtained with a technique called Grad-CAM. Yang said, “Because Grad-CAM heat map scores are based on gradients, this technique can be used to explain predictions. In our case, it can explain a score that represents why the input image and the input text are paired. And if the two are paired, then our model will indicate the location of the input text on the image.” The team proposed Attention Mask Consistency (AMC), a new objective that aligns Grad-CAM heat maps with box annotations provided by humans whenever those are available.
Ordóñez believes this is the most impressive aspect of Yang’s work on visual grounding with AMC. He said, “Instead of optimizing a model to produce better answers, the AMC model is optimized to produce better explanations to produce its answers."
“This process does not require modifying an existing model architecture or adding new parameters, it mostly requires tuning these models with some relatively small amount of extra data containing human explanations in the form of boxes or potentially other forms of feedback. When Ziyan presents our model at CVPR, I believe the participants will be excited not only about what our method does, but also the possibilities it opens in this direction to further improve other models through carefully curated human guidance.”
Based on the number of citations, Google Scholar ranks CVPR as one of the top venues for scientific dissemination in all fields of research. The conference at which Yang is presenting is surpassed only by the journals Nature, The New England Journal of Medicine, and Science.
“While these metrics are imperfect, it goes to show at least the amount of interest in this area of research, the importance of this event beyond computer vision, and the amount of resources being devoted globally to push forward impactful research in this area,” said Ordóñez.
He said Yang’s contributions to the vislang team have been manifold. “In addition to her publications in natural language processing, computer vision and artificial intelligence, she has mentored several undergraduate and visiting students in the group and helped establish and maintain a long-term collaboration with Adobe Research.”
Their most recent paper — which prompted Yang’s interactive demo — is the result of a collaboration with Adobe research scientists Kushal Kafle and Franck Dernoncourt. The demo may be informative and fun to use, but Yang is most excited by their model’s ability to provide visual explanations for arbitrary queries in the same way that ChatGPT is able to provide answers for seemingly arbitrary questions.
Another downstream task, Referring Expression Comprehension, is one Ordóñez is happy to revisit. He said, “The problem consists of automatically finding the location of an object, given an image and a textual description referring to that object. Several years ago — when I was a Ph.D. student myself — I worked on building one of the first large scale benchmarks for this problem. At the time, our systems could only localize objects from a very limited set of object types; now we can do this for a much larger set of objects, as shown in our demo. Other downstream tasks could include multimedia content summarization, image search, product recommendations, etc.”